
Implementing a distributed lock in microservices mechanism is a critical aspect when developing scalable microservices. Distributed locks help ensure that multiple processes or services do not concurrently modify shared resources, avoiding race conditions and ensuring data consistency. In this comprehensive guide, we will explore how to implement a distributed lock using Redis in a microservices architecture, explain the underlying principles, and provide real-time examples to help you understand the concept.
Distributed Locks in Microservices
Microservices architectures have become the de facto standard for building scalable and robust applications. However, when multiple services interact with shared resources, coordination becomes a challenge. Distributed locks offer an effective solution to manage concurrent access and ensure that only one service can modify a resource at any given time.
In this blog, we discuss how Redis, an in-memory data structure store, can be used to implement distributed locks. Redis is known for its high performance, scalability, and simplicity, making it a popular choice among developers. We will dive into the core concepts of distributed locking, explore Redis commands that make it possible, and walk through code examples that illustrate how to safely acquire and release locks in a microservices environment.
Understanding Distributed Locks
A distributed lock is a mechanism used to synchronize access to a shared resource across multiple nodes or processes. Unlike local locks that work within a single application instance, distributed locks operate in a networked environment where multiple instances might try to modify the same resource simultaneously.
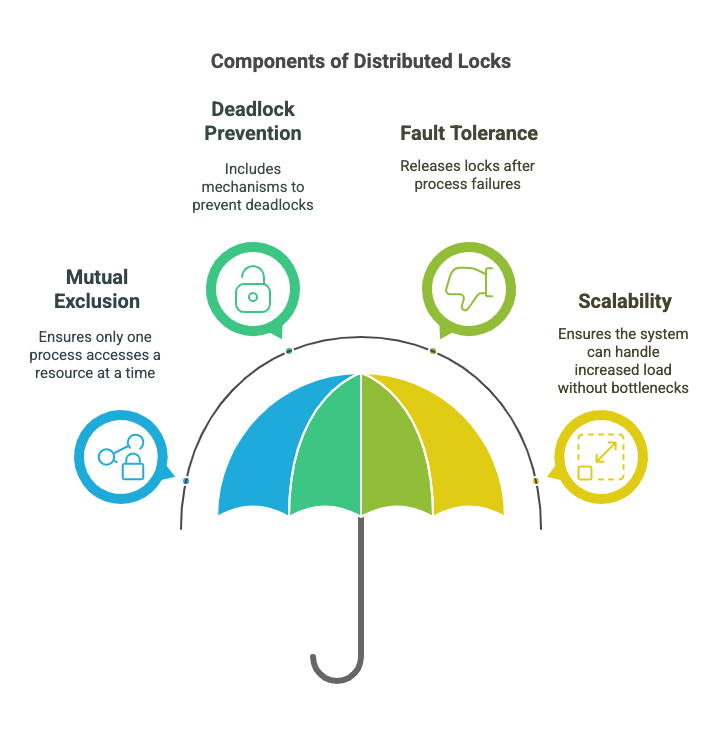
Key Concepts:
- Mutual Exclusion: Ensures that only one process can access a resource at a time.
- Deadlock Prevention: A robust lock implementation should include mechanisms to prevent deadlocks by having a timeout mechanism for locks.
- Fault Tolerance: In the event of a process failure, the lock should be released so that other processes can continue functioning.
- Scalability: The locking mechanism should not become a bottleneck as the number of services scales.
Distributed locks are particularly useful when dealing with critical operations like updating inventory counts, processing financial transactions, or managing user sessions.
Why Redis?
Redis is widely adopted for implementing distributed locks due to its simplicity and performance advantages:
- High Performance: Redis operates entirely in-memory, offering sub-millisecond response times which are essential for time-critical operations.
- Atomic Operations: Redis supports atomic commands such as
SETwith the NX (Not eXists) and EX (Expire) options. These commands ensure that lock acquisition is done safely in concurrent environments. - Persistence Options: Although primarily an in-memory store, Redis can be configured to persist data, ensuring that the system can recover in case of a crash.
- Simplicity and Versatility: The straightforward command set of Redis makes it easy to implement distributed locks without heavy infrastructure overhead.
Redis is not only effective for locking but also widely used as a cache, message broker, and session store. Its versatility makes it a compelling choice for modern microservices architectures.
The Distributed Lock Algorithm
One of the most popular approaches to implement distributed locks with Redis is to use the SET command with specific flags:
The SET Command with NX and EX:
- NX: Ensures that the key is set only if it does not already exist. This prevents overwriting an existing lock.
- EX: Sets an expiration time for the key. This prevents deadlocks by ensuring that the lock is automatically released after a certain period.
The command is structured as follows:
- lock_key: The identifier for the lock.
- unique_identifier: A unique token for the process trying to acquire the lock. This helps in ensuring that only the lock owner can release the lock.
- timeout: The expiration time to automatically release the lock if the process fails to do so manually.
The Process:
- Acquiring the Lock: A process attempts to set the lock key with a unique identifier using the above command.
- Operation Execution: If the lock is acquired, the process performs its critical section tasks.
- Releasing the Lock: Once the task is complete, the process releases the lock by deleting the key, but only if the key's value matches the unique identifier.
Implementing Distributed Locks with Redis
Let’s delve into the steps and code examples necessary to implement a distributed lock using Redis in a microservices environment.
Setting Up Redis
Before diving into the code, ensure that Redis is installed and running on your system. For local development, you can use Docker to set up Redis quickly:
This command sets up a Redis container running on the default port 6379.
Creating a Lock with SET Command
Below is a simple example in Node.js that demonstrates acquiring a distributed lock using the Redis client:
In this code:
- We use Redis’
SETcommand with NX and EX flags to try and obtain a lock. - A unique identifier (
LOCK_VALUE) is used to ensure that the process releasing the lock is the same one that acquired it. - A Lua script is used to safely release the lock by ensuring atomicity—only deleting the lock if the stored value matches the unique identifier.
Releasing the Lock Safely
Releasing the lock safely is as crucial as acquiring it. If a process crashes or encounters an error while holding the lock, the expiration set by the EX parameter ensures that the lock is released automatically after a timeout. However, in normal conditions, you should release the lock as soon as your critical section is complete.
The Lua script ensures that the lock is only released by the process that owns it, preventing other processes from inadvertently deleting the lock. This mechanism is critical in a distributed environment where multiple processes might contend for the same lock.
Real-Time Examples and Use Cases
1. E-commerce Order Processing
Imagine an e-commerce application where multiple microservices are involved in processing orders. One microservice is responsible for managing the inventory, while another handles payment processing. When an order is placed, it is crucial to prevent overselling of products by ensuring that inventory counts are updated atomically.
Scenario:
- The inventory service uses a distributed lock to ensure that when multiple orders are processed concurrently, the product stock is updated correctly.
- If the lock is not acquired, the service may choose to queue the order or send a notification to try again later.
2. Financial Transactions
In financial systems, concurrent transactions on the same account can lead to discrepancies and data corruption. A distributed lock can ensure that one transaction completes before another begins, maintaining data integrity.
Scenario:
- A banking microservice uses Redis locks to serialize transactions on a user's account.
- Each transaction acquires a lock before processing the withdrawal or deposit, ensuring that balance updates occur sequentially and accurately.
3. Content Management Systems (CMS)
Content management systems often have multiple editors working simultaneously. Distributed locks can prevent simultaneous updates to the same document, avoiding conflicts and data loss.
Scenario:
- A collaborative document editing service uses Redis locks to ensure that when one editor is making changes, others are notified or prevented from editing until the lock is released.
- This improves the user experience by reducing merge conflicts and maintaining data consistency.
4. Microservices Orchestration
In complex microservices architectures, certain operations—such as scheduled tasks or data migrations—may need to run exclusively. Distributed locks ensure that these operations do not run concurrently, which could otherwise lead to system instability.
Scenario:
- A data migration job in a distributed system acquires a lock before starting the migration process.
- Once the migration is complete, the lock is released, allowing another instance to pick up the task if necessary.
Best Practices and Considerations
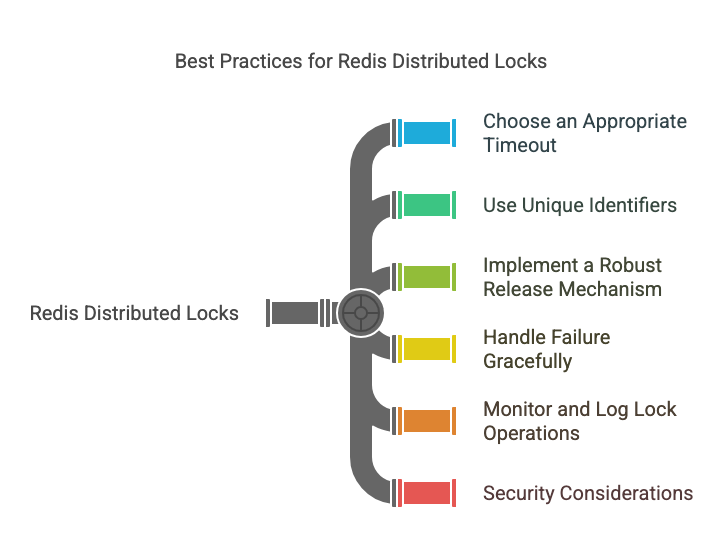
When implementing distributed locks using Redis, consider the following best practices:
1. Choose an Appropriate Timeout
Setting the expiration time (EX parameter) is crucial. The timeout should be long enough to allow the process to complete its task, but not so long that it prevents others from acquiring the lock if a process crashes. This balance is key to preventing deadlocks.
2. Use Unique Identifiers
Always use a unique identifier for each lock acquisition attempt. This prevents accidental release of a lock by a process that does not own it. The unique token can be generated using UUID libraries or similar mechanisms.
3. Implement a Robust Release Mechanism
Using a Lua script to atomically check and release the lock is highly recommended. This approach ensures that only the process that acquired the lock can release it, thus maintaining data integrity and avoiding race conditions.
4. Handle Failure Gracefully
Your application should be designed to handle cases where a lock cannot be acquired. This could involve retry mechanisms with exponential backoff or alternative workflows to ensure that the service remains responsive even under contention.
5. Monitor and Log Lock Operations
Logging every attempt to acquire and release locks can help in troubleshooting and understanding system behavior under load. Monitoring these operations provides insights into potential performance bottlenecks or deadlock scenarios.
6. Security Considerations
Ensure that your Redis instance is properly secured, especially when used in a production environment. Use authentication, secure connections (TLS), and restrict access to the Redis server using firewalls or security groups.
Potential Pitfalls and How to Avoid Them
Implementing distributed locks comes with its own set of challenges. Here are some common pitfalls and strategies to avoid them:
1. Over-Reliance on Lock Expiration
While expiration times prevent deadlocks, they might also lead to scenarios where a process takes longer than expected, causing the lock to expire prematurely. To mitigate this, consider using mechanisms to extend the lock if the process is still active, but do so carefully to avoid indefinite locking.
2. Network Latency and Failures
In a distributed system, network latency and temporary connectivity issues can affect lock acquisition and release. Implementing robust retry policies and fallback mechanisms will help ensure system stability in such scenarios.
3. Single Point of Failure
Redis, when used as a single instance, can become a single point of failure. To address this, consider using Redis Sentinel or a clustered configuration that ensures high availability and automatic failover.
4. Inconsistent Lock Release
Ensure that your release mechanism is atomic and that the lock is always released, even in cases of errors or exceptions. Using Lua scripting and proper error handling can significantly reduce the risk of locks being left in an inconsistent state.
Conclusion
Implementing a distributed lock with Redis in microservices is a powerful way to manage concurrent access to shared resources. By using Redis’ atomic operations and employing best practices such as using unique identifiers, setting appropriate timeouts, and employing Lua scripts for atomic lock release, you can build robust, scalable, and reliable microservices.
In this guide, we covered the fundamentals of distributed locks, explored why Redis is an ideal candidate for implementing them, and walked through real-time examples from e-commerce, financial transactions, content management, and microservices orchestration. By following the guidelines and best practices outlined above, you can ensure that your microservices architecture remains resilient, responsive, and ready to scale.
Frequently Asked Questions
Q1: What is a distributed lock and why is it important?
A distributed lock ensures that only one process can access a shared resource at a time. This is critical in microservices architectures to prevent race conditions, data corruption, and to maintain consistency.
Q2: How does Redis help in implementing distributed locks?
Redis offers atomic operations, particularly the SET command with NX and EX options, making it easy to implement locks. Its in-memory nature provides high performance, and features like persistence and clustering add robustness to the solution.
Q3: What happens if a process crashes while holding the lock?
If a process crashes, the expiration set by the EX parameter ensures that the lock is automatically released after the timeout period, allowing other processes to acquire the lock.
Q4: Can distributed locks be used in any programming language?
Yes, Redis clients exist for multiple programming languages including Node.js, Python, Java, and Go. The core concept remains the same across languages, though implementation details may vary.
Q5: How can I ensure that my Redis instance is secure?
Security best practices include using strong authentication, enabling TLS for encrypted connections, restricting access to trusted networks, and leveraging Redis Sentinel or clustering for high availability.
Implementing a distributed lock using Redis is not only a technical necessity in many modern applications but also a best practice to ensure system integrity in microservices. With careful planning, thoughtful design, and adherence to best practices, you can build a distributed system that is robust, scalable, and capable of handling the complexities of concurrent operations.
This comprehensive guide has provided detailed insights and actionable examples to help you implement and manage distributed locks using Redis. Whether you are developing an e-commerce platform, managing financial transactions, or orchestrating microservices, these techniques will empower you to maintain data consistency and improve overall system reliability.
Embrace the power of distributed locks with Redis and transform your microservices architecture into a more resilient and efficient ecosystem.



