
Apache Kafka has emerged as a key player in the world of event-driven architecture, serving as a reliable foundation for real-time data pipelines and streaming applications. Central to Kafka's distributed architecture are Kafka Brokers, which act as the backbone of the system. In this blog, we’ll break down what Kafka Brokers are, their roles and responsibilities, and how they seamlessly integrate into Kafka's larger ecosystem. By the end, you'll have a clear understanding of how these components power the real-time data flow that makes Kafka so powerful.
What is a Kafka Broker?
A Kafka Broker is a server that plays a crucial role in managing the data flow within a Kafka cluster. It hosts partitions of topics, stores the data, and handles requests from producers and consumers. In a typical Kafka setup, multiple brokers work together to evenly distribute data and process requests efficiently. This collaborative setup ensures fault tolerance, scalability, and high availability, making Kafka reliable for real-time data streaming and processing.
Key Responsibilities of Kafka Brokers
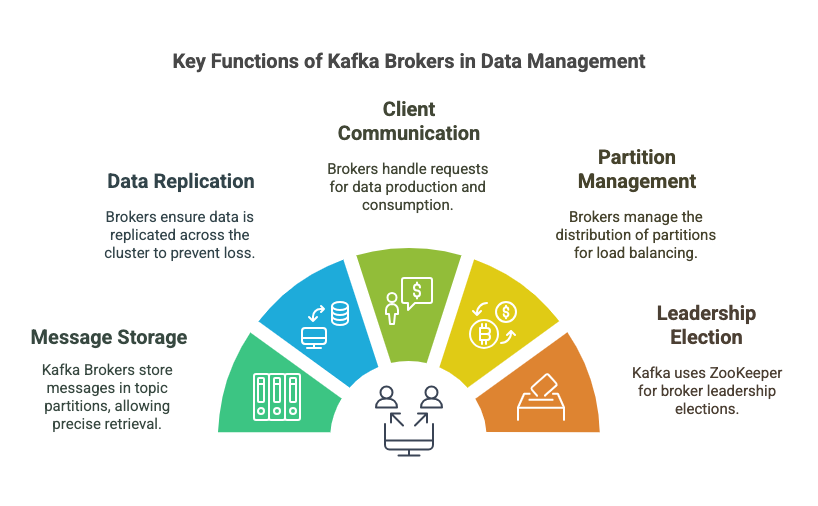
- Message Storage: Kafka Brokers store messages in topic partitions. Each message is uniquely identified by an offset, allowing precise retrieval.
- Data Replication: Brokers ensure data is replicated across the cluster to prevent data loss. This replication is managed by the partition leader and its replicas.
- Client Communication: Brokers handle client requests for data production and consumption. Producers send data to brokers, and consumers fetch data from brokers.
- Partition Management: Brokers manage the distribution of partitions across the cluster, ensuring even load distribution and balancing.
- Leadership Election: In the event of a broker failure, Kafka uses ZooKeeper to manage broker leadership elections to ensure cluster stability and consistency.
How Kafka Brokers Work Together
In a Kafka cluster, brokers collaborate to ensure seamless and efficient data flow:
- Cluster Coordination: Kafka relies on ZooKeeper (or KRaft in newer versions) to manage the cluster. This includes coordinating brokers, electing partition leaders, and handling configuration settings.
- Load Balancing: Kafka automatically distributes partitions across brokers to optimize performance. If changes occur, such as brokers being added or removed, partitions are redistributed to maintain balance.
- High Availability: Kafka ensures data reliability by replicating partitions across multiple brokers. Even if a broker fails, the data remains accessible through replicas on other brokers, guaranteeing fault tolerance and uninterrupted operation.
Kafka Components Overview
To visualize the Kafka Broker components, consider the following diagram:
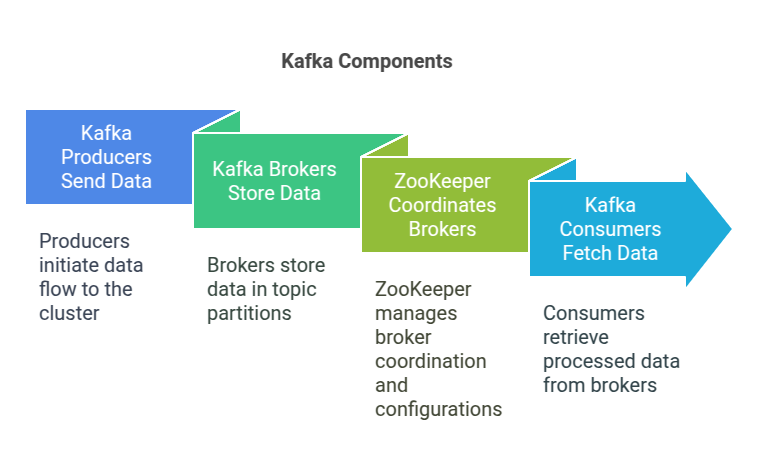
- Kafka Producers: send data to the Kafka cluster.
- Kafka Brokers: receive and store the data in partitions within topics.
- ZooKeeper: coordinates the brokers, managing leader elections and configurations.
- Kafka Consumers: fetch data from the brokers.
This architecture ensures data durability, scalability, and efficient data processing across distributed systems.
Conclusion
Kafka Brokers are the backbone of Kafka clusters, providing the essential services needed for robust, scalable, and fault-tolerant data streaming and processing. Understanding their roles and functionalities helps in designing and maintaining efficient Kafka-based solutions. With Kafka Brokers, you can ensure that your data pipelines are reliable, performant, and ready to handle the demands of modern data-driven applications.
By leveraging the power of Kafka Brokers, organizations can build resilient event-driven architectures that can scale seamlessly and handle massive data volumes with ease.
This blog has covered the basics of Kafka Brokers. If you have further questions or need deeper insights into specific aspects of Kafka, feel free to reach out or explore more detailed Kafka documentation and resources.


